


dlthub 12: Feb ‘25

Welcome back to our product newsletter. We skipped the last edition because we were nose-down building new things, which should make this issue even more interesting.
1. Community section
The last time we talked about the community, it was about November. In Dec and Jan, usage of dlt rose 30-60% across the board, from new sources developed by the community (now over 20k) to users in production, sources in production, and volumes of data loaded.
Being product led growth is a blessing when everything comes together
At dlt, we believe in product-led growth. While some companies allocate 50% of their budget to marketing, we invest 90% into making the product better. Our growth team’s efforts focus on what truly matters: better documentation, better support, better education. Despite being a company an order of magnitude smaller than many vendors, we’re on our way to becoming the standard ingestion library for data engineering.
But a product-led growth motion relies on users to share their successes with the broader audience.
This is where you help
We’d like to encourage and support your voice. If you’d like to give back, here’s how you can contribute:
Recommend dlt to your peers IRL or on social media
Celebrate your wins in public! If dlt helped you succeed, share the story and spread the joy.
Writing about dlt? Let us know! We’d love to amplify your voice.
Speaking at meetups? We can support you with swag, awareness, or feedback.
Want to teach dlt? We’re here to back your education initiatives.
Short on time but have a story to share? We can write up case studies for you; just hop on a quick chat with us.
For any of the above, reach out to myself (Adrian) or Alena on Slack. We’d love to collaborate and help you share your experience.
Special thanks to Community voices
Reddit: Shoutout to mertertrern, muneriver, molodyets, DolphinScheduler1, Yabakebi, kakoni, and burnbay for mentioning dlt on Reddit!
Linkedin: A big shoutout to Rakesh Gupta, Nasrin Mokhtarian, Alexey Grigorev, Jatan Sahu, Hugo Lu, Mateusz Paździor, Tower.dev, Hugo Carnicelli, Jeff Lewis, Jesse Stanley, Albrecht Mariz, Bijil Subhash, Paul Marcombes, Luca Milan, Alejandro G. Bueno, Bela Wiertz, Richard Shenghua, Ridvan Sibic, Mattias Thalén, Carlos A. Crespo, Julien Bovet, and Romain Ferraton for mentioning dlt!
Thank you to our education students who talked about it on Linkedin: Miguel P, Hasan Green, Hrushikesh Thorat, Antoine Giraud, Laurin Brechter, Jason B. Hart, Ngoc Anh Tran, Sourabh Lakhera, Denise Lewis, Vlado P., Kadipa A., Jude Ndu, Kunal Jhaveri, Robin De Neef, Nkemakolam O., Martin Chakarov, Jeff Skoldberg, Denis Krivenko, Lonnie Morgan Jr, Lenara S., Ismael Jiménez, Sergio Eguizábal Alguacil, Carlos Isaias Quiala González, Xavier Thoraval, Yuki Kakegawa for getting certified as dlt specialists and sharing that on Linked In.
Bluesky: Thanks to Bijil Subhash, fab, josh, David Jayatillake and vasilijee for mentions on Bluesky. And to Andrey Cheptsov and Martin Salo for mentioning dlt in their X posts.
Interesting content:
New to dlt pipelines? Nkem Onyemachi has written a fantastic guide to help beginners get started!
Building with Fabric? Rakesh Gupta has created the Fabric dlthub series to bridge the gap between dlt and Fabric users.
Ángel RC from SDG Group showcases how dlt simplifies API data extraction, normalization, and loading for supermarket price tracking. Read the full use case here.
Ismail Simsek demonstrates how to use Debezium and dlt to build a Change Data Capture (CDC) pipeline. Read the full post here.
Building ETL/ELT with dlt, Dario Radečić explores data extraction, transformation, and loading across various sources. Read more here.
Community contributors
@gregorywaynepower made their first contribution in #2332
@jonbiemond made their first contribution in #2207
@gaatjeniksaan made their first contribution in #2244
@lpillmann made their first contribution in #2255
2. What we recently did
dlt+ Early access is here!
Since our November roadshow, we have worked with our early design partners to push forward dlt+ development. In the last two weeks (announcement post), we started to release early features from dlt+, our framework for running dlt pipelines in production, in early access (EA) with many more in pilot and development (dev).
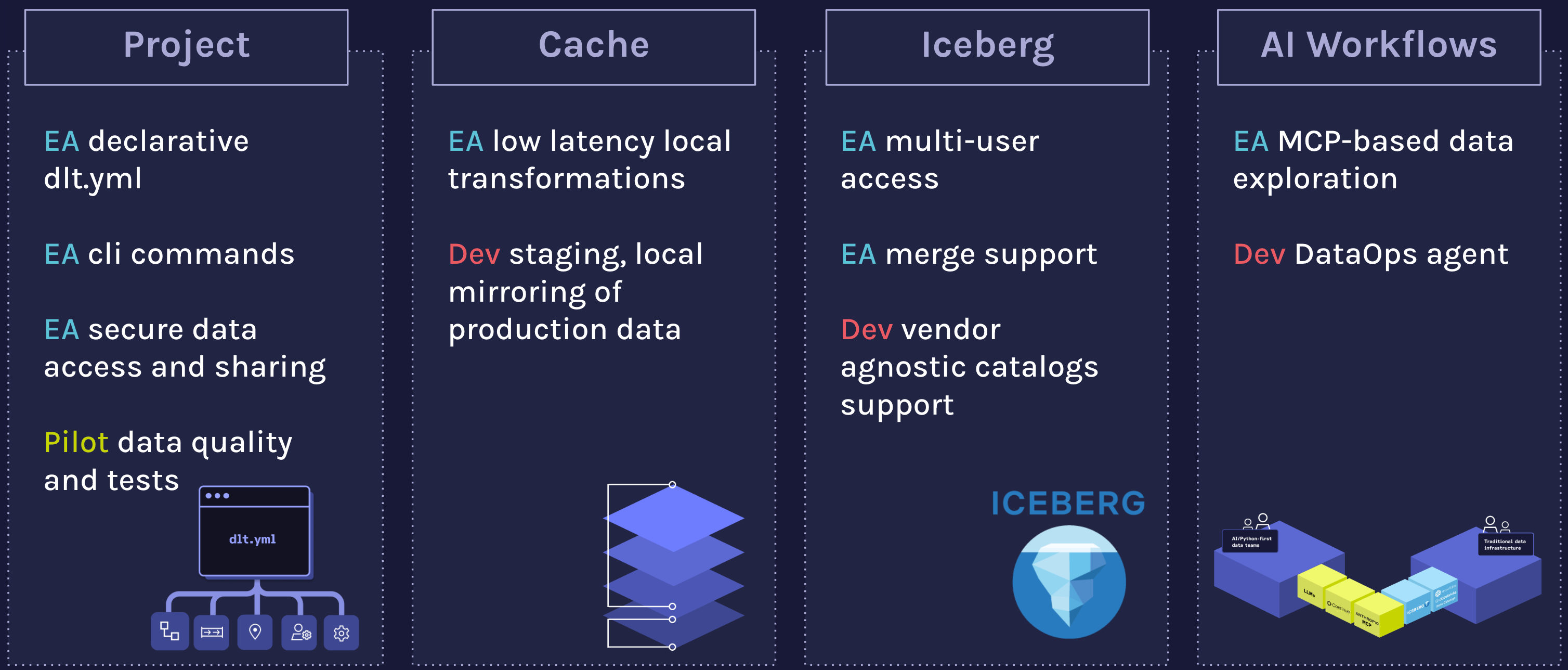
So far, we started to communicate about 3 parts of dlt+
1. dlt+ Project - a declarative way to work in teams on dlt pipelines

In a dlt+ Project, your whole team can work on dlt sources, destinations, and pipelines in a standardized way via a YAML Project manifest. Enable collaboration in multidisciplinary teams and keep stakeholders aligned with a single source of truth.
2. dlt+ Cache - a developer environment for data engineers

Shift yourself left with the dlt+ Cache, a complete testing and validation layer for data transformations. Run your transformations locally to avoid testing in production and save cloud costs.
3. A set of initial AI Workflows for data engineers in partnership with Continue
In Sep’ 24 OpenAI’s O1 preview was the first LLM to index dlt, unlocking a much better ChatGPT experience. We started to hear about the initial happy use cases of dlt users Cursor.
To unlock AI workflows for data engineers further, we partnered with Continue. Continue 1.0 got released this week, and it enables developers to create, share, and use custom AI code assistants with open-source IDE extensions that can now seamlessly leverage a vibrant hub of models, context, and other building blocks. As the initial set of AI workflows we offer:

A dlt assistant that dlt developers can use to chat with the dlt documentation from the IDE and pass it to the LLM to help you write dlt code. Using tools, your preferred LLM will be able to inspect your pipeline schema and run text-to-SQL queries.
A dlt+ assistant that extends the dlt assistant with support for dlt+ Project features. This includes kick-starting dlt+ projects, managing your catalog of sources, destinations, & pipelines, and running pipeline on your behalf for a tight development feedback loop.
Additionally, we also release an initial set of building blocks, including two Anthropic MCP servers, that allow developers to build their own dlt and dlt+ custom assistants.
This is our first step in making LLM-powered data engineering actually work, moving beyond rigid SaaS connectors to trusted, customizable AI systems. Check out the dlt assistants & building blocks on Continue Hub and start building faster today!
You can follow along our dlt+ progress in our evolving dlt+ docs. We only have capacity to work with up to 20 early access candidates in the couple of weeks, so if you are interested waste no time to apply here!
Education
This year, we are doubling down on offering education.
You can now Sign up to our education waiting list to get notified of any upcoming courses. We plan to do a lot more this year on a variety of themes that are helpful to data engineers.
If you’d like to offer your own course, workshop or educational content to the dltHub community, reach out to myself (Adrian) or Alena on Slack.
We also prepared a repository where you can find our async courses or older content: https://github.com/dlt-hub/dlthub-education.
Consulting Partnerships
We opened our partner program to a few more close partners. As we prepare to make dlt+ available commercially, we welcome more consulting partnerships to help with delivery. For the dlt OSS-focused partners, we offer co-marketing opportunities.
If you are a freelancer or consulting agency and are interested in participating, please join our partnership queue, and excuse the wait. We plan to onboard you all before the dlt+ public launch.
Feature developments
dlt OSS
Databricks destination major improvements - uses internal staging, auto-creates volumes, and detects credentials automatically
Expanded SQLAlchemy destination support (Oracle, DB2, SAP HANA, Exasol, Trino, etc.)
Subcommands enabled for environments without CLI installed
REST API Paginator: Automatically paginates using a next-page cursor in the response header
Common tmp_dir & Ref Importer: Centralizes local file storage, applies consistent database naming, and introduces flexible string references for destinations and sources
3. Coming up next
Education
As we mentioned above about education, we will be announcing new events via the education newsletter/mailing list/waiting list. Besides some really cool courses we are working on, we are also interested to give you a voice
Upcoming events:
ELT with dlt Advanced course: Easter edition TBA, sign up here to be notified!
An Iceberg workshop in San Francisco as part of the Iceberg Summit on April 8th/9th
Courses:
Python ELT course mid-level to senior: Freecodecamp edition TBA, sign up here to be notified!
Product
On the product side, we are busy with the rest of the dlt+, and with taking your early access feedback and improving the dlt+ Cache and Projects for eventual public release.
💡 Get involved: See our short-term roadmap here and tell us what you need.