


dlthub September ‘24: dlt 1.0 & towards a portable data lake

1. Community section
The dltHub Community is growing, and we are seeing more advocacy from the community than ever before.
We are deeply grateful for your activity in this area.
While we focus our energy on developing a standard, it's your voice in the open source that cuts through the noise and helps other data people distinguish between various solutions.
dlt usage stats
Usage is accelerating. In the last 12 months, the community has built over 10k private sources and over 250 private destinations. Half of this happened in the last 3 months. We’ve recently announced 1,000 customers in production.
dlt in blogs:
dlt as AI enabler: Custom autocomplete model using Continue and Unsloth on Google Colab.
A blog post from Modal which is fast and cheap and you should check it out.
Medium tutorial showcasing a local dlt + postgres + scd test
The integrated ecosystem is growing
No data engineer wants to be human middleware connecting disparate tools to work together. dlt is part of the open source movement towards composable data stacks.
Collaboration is the topic: Besides integration between tools, composability gives us integration between the workflows that occur in those tools. This partly addresses the need for more collaboration across the data stack, as identified for example in the recent “one dbt” product announcement.
dlt + SQLMesh ecosystem integration
Solving a fragmented data ecosystem is possible when your tools talk to each other. SQLMesh is adding a dlt integration to enable generation of incremental scaffolding.
dlt + dbt integration
dlt team created a similar integration with dlt, giving birth to a dlt-dbt generator.
Additionally, we are experimenting with data model materialisations and created a dimensional modelling tool. With this tool we tackled declarative dimensional modelling, enabling us to generate full models in one swoop. But to enable it to shine, the dimensional modelling should happen not on raw data, and instead should run on a conformed entity layer that represents actions and entities in flat tables. We may revisit this in the context of the portable data lake.
Community contributions
Correct wrong code example for apply_hints( incremental(xx) ) by @w0ut0 in #1785
Fix typo "frequenly" by @ruudwelten in #1800
Fix/1849 Do Not Parse Ignored Empty Responses by @TheOneTrueAnt in #1851
Update installation.md by @erikjamesmason in #1899
Update weaviate reference by @emmanuel-ferdman in #1896
fix: UUIDs are not an unknown data type (logging) by @neuromantik33 in #1914
fix: PageNumberPaginator not reset when iterating through multiple pa… by @paul-godhouse in #1924
Feat/1922 rest api source add mulitple path parameters by @TheOneTrueAnt in #1923
2. What we recently did
Version 1.0 is out
An enterprise-ready Python library for data movement that’s all about efficiency and autonomy.
See the announcement and note Marcin’s take on how dlt has evolved, with the continuous support of our community, into a comprehensive Python library for moving data. It integrates seamlessly with the Modern Data Stack. It works with high-performance Python data libraries like PyArrow, Polars, Ibis, DuckDB, and Delta-RS, efficiently processing industrial-scale data, even in constrained environments like AWS Lambda.
Towards a portable data lake; the dev env for building and working with data platforms.
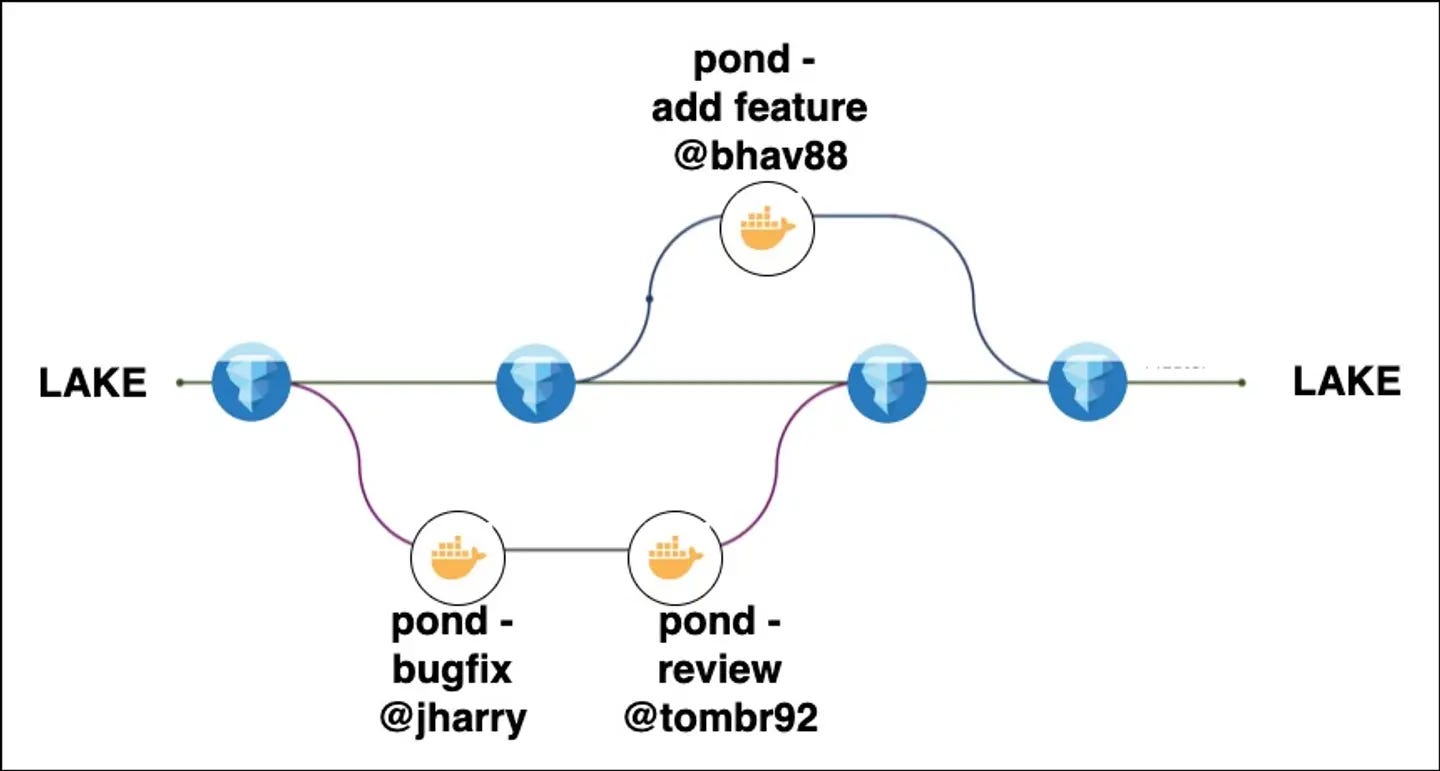
We recently discussed the portable data lake in this blog post.
Additionally, we went on the Data Engineering Podcast to talk about dlt’s role as a library rather than a platform, and its integration with lakehouse architectures and AI application frameworks.
In recent weeks we have been working on making the portable data lake reality. By joining us as an early design partner, you get early access and your feedback will be critical in shaping our direction. We still have a few design partner slots open.
Apply for a design partnership or join the waiting list

Slack support changes
To help our team focus on building, we are adding the docs helper to Slack as a first line of support. We are keeping an eye on your feedback and are iterating quickly.
Feature developments
Core
SQL alchemy destination added as part of core. This enables some 30+ databases
SQL, Filesystem and REST API sources moved to core for better support.
Small improvements to REST API source, among others the ability to combine code and config resources.
Small improvements to Filesystem source, among others sftp.
Read the detailed commit/release logs here: dlt, Sources.
3. Coming up next
Meet us in SF, NY, Paris, Berlin and discuss open data lakes & dlt
In the coming weeks, we will be on the road and looking to engage in in-person conversations where dlt is heading. We are organising a series of events around open data lakes, as a way to further the dialogue in this direction. In November we plan to have an initial set of four events:
San Francisco: Wednesday the 6th of November: Open Data Lake(side) Gathering
New York, Tuesday 12th of November: Open Data Lake Dinner
Paris, Tuesday 19th of November: Data Lakes in Production
Berlin Thursday 21st of November: dlt demos & Portable Data Lake Reveal
If you are interested in any of these events, then let us know. Some of them are still being organised and we will provide links with details soon. We will show demos from companies using dlt and of our portable data lake. We are also interested to meet you in these locations outside of these events and learn about what you are building with dlt.
We are also considering an event around AWS Re:Invent in Las Vegas in December, London and Amsterdam in January. Any additional locations we should visit? Let us know!

Workshop: Portable data lake 8th of Nov.
Sign up here!
Many of you are building some version of this open or portable data lake. We are organising a workshop to share our learnings and offer a pathway towards building such lakes. We will explore what we can do with current technology and build a simple proof of concept together. We will then show you how we are putting together our version.
Upcoming development
Our focus this month is on the building of the portable data lake. As with everything new and of some complexity, it’s difficult to describe it well. To this end, we are preparing some early demos. If you want to give the portable data lake a try, join the waiting list to be updated on progress.
On the dlt side, we are working on features like chunk and embedding management in LanceDB, user-provided text splitters for document chunking, decluttering the REST API, and allowing table/column modeling in dlt schema.
💡 Get involved: See our short-term roadmap here and tell us what you need.
Thank you all for being part of this incredible journey.
Together, with your help, in little over a year we irreversibly changed the state of data ingestion in the ecosystem from complex and expensive to simple and empowering.
As an open core company, we build dlt as a free open source standard.
We currently offer commercial support focused on your enablement and acceleration of building data platforms with dlt. Our Portable Data Lake is looking to build on that and deliver a better, more effective developer experience along with adding collaboration, portability, and cost efficiency to your data platform.
- Adrian, data engineer and co-founder of dlt